[Highlights for the busy: de-bunking standard “Bayes is optimal” arguments; frequentist Solomonoff induction; and a description of the online learning framework.]
Short summary. This essay makes many points, each of which I think is worth reading, but if you are only going to understand one point I think it should be “Myth 5″ below, which describes the online learning framework as a response to the claim that frequentist methods need to make strong modeling assumptions. Among other things, online learning allows me to perform the following remarkable feat: if I’m betting on horses, and I get to place bets after watching other people bet but before seeing which horse wins the race, then I can guarantee that after a relatively small number of races, I will do almost as well overall as the best other person, even if the number of other people is very large (say, 1 billion), and their performance is correlated in complicated ways.
If you’re only going to understand two points, then also read about the frequentist version of Solomonoff induction, which is described in “Myth 6″.
Main article. I’ve already written one essay on Bayesian vs. frequentist statistics. In that essay, I argued for a balanced, pragmatic approach in which we think of the two families of methods as a collection of tools to be used as appropriate. Since I’m currently feeling contrarian, this essay will be far less balanced and will argue explicitly against Bayesian methods and in favor of frequentist methods. I hope this will be forgiven as so much other writing goes in the opposite direction of unabashedly defending Bayes. I should note that this essay is partially inspired by some of Cosma Shalizi’s blog posts, such as this one.
This essay will start by listing a series of myths, then debunk them one-by-one. My main motivation for this is that Bayesian approaches seem to be highly popularized, to the point that one may get the impression that they are the uncontroversially superior method of doing statistics. I actually think the opposite is true: I think most statisticans would for the most part defend frequentist methods, although there are also many departments that are decidedly Bayesian (e.g. many places in England, as well as some U.S. universities like Columbia). I have a lot of respect for many of the people at these universities, such as Andrew Gelman and Philip Dawid, but I worry that many of the other proponents of Bayes (most of them non-statisticians) tend to oversell Bayesian methods or undersell alternative methodologies.
If you are like me from, say, two years ago, you are firmly convinced that Bayesian methods are superior and that you have knockdown arguments in favor of this. If this is the case, then I hope this essay will give you an experience that I myself found life-altering: the experience of having a way of thinking that seemed unquestionably true slowly dissolve into just one of many imperfect models of reality. This experience helped me gain more explicit appreciation for the skill of viewing the world from many different angles, and of distinguishing between a very successful paradigm and reality.
If you are not like me, then you may have had the experience of bringing up one of many reasonable objections to normative Bayesian epistemology, and having it shot down by one of many “standard” arguments that seem wrong but not for easy-to-articulate reasons. I hope to lend some reprieve to those of you in this camp, by providing a collection of “standard” replies to these standard arguments.
I will start with the myths (and responses) that I think will require the least technical background and be most interesting to a general audience. Toward the end, I deal with some attacks on frequentist methods that I believe amount to technical claims that are demonstrably false; doing so involves more math. Also, I should note that for the sake of simplicity I’ve labeled everything that is non-Bayesian as a “frequentist” method, even though I think there’s actually a fair amount of variation among these methods, although also a fair amount of overlap (e.g. I’m throwing in statistical learning theory with minimax estimation, which certainly have a lot of overlap in ideas but were also in some sense developed by different communities).
The Myths:
- Bayesian methods are optimal.
- Bayesian methods are optimal except for computational considerations.
- We can deal with computational constraints simply by making approximations to Bayes.
- The prior isn’t a big deal because Bayesians can always share likelihood ratios.
- Frequentist methods need to assume their model is correct, or that the data are i.i.d.
- Frequentist methods can only deal with simple models, and make arbitrary cutoffs in model complexity (aka: “I’m Bayesian because I want to do Solomonoff induction”).
- Frequentist methods hide their assumptions while Bayesian methods make assumptions explicit.
- Frequentist methods are fragile, Bayesian methods are robust.
- Frequentist methods are responsible for bad science
- Frequentist methods are unprincipled/hacky.
- Frequentist methods have no promising approach to computationally bounded inference.
Myth 1: Bayesian methods are optimal. Presumably when most people say this they are thinking of either Dutch-booking or the complete class theorem. Roughly what these say are the following:
Dutch-book argument: Every coherent set of beliefs can be modeled as a subjective probability distribution. (Roughly, coherent means “unable to be Dutch-booked”.)
Complete class theorem: Every non-Bayesian method is worse than some Bayesian method (in the sense of performing deterministically at least as poorly in every possible world).
Let’s unpack both of these. My high-level argument regarding Dutch books is that I would much rather spend my time trying to correspond with reality than trying to be internally consistent. More concretely, the Dutch-book argument says that if for every bet you force me to take one side or the other, then unless I’m Bayesian there’s a collection of bets that will cause me to lose money for sure. I don’t find this very compelling. This seems analogous to the situation where there’s some quant at Jane Street, and they’re about to run code that will make thousands of dollars trading stocks, and someone comes up to them and says “Wait! You should add checks to your code to make sure that no subset of your trades will lose you money!” This just doesn’t seem worth the quant’s time, it will slow down the code substantially, and instead the quant should be writing the next program to make thousands more dollars. This is basically what dutch-booking arguments seem like to me.
Moving on, the complete class theorem says that for any decision rule, I can do better by replacing it with some Bayesian decision rule. But this injunction is not useful in practice, because it doesn’t say anything about which decision rule I should replace it with. Of course, if you hand me a decision rule and give me infinite computational resources, then I can hand you back a Bayesian method that will perform better. But it still might not perform well. All the complete class theorem says is that every local optimum is Bayesan. To be a useful theory of epistemology, I need a prescription for how, in the first place, I am to arrive at a good decision rule, not just a locally optimal one. And this is something that frequentist methods do provide, to a far greater extent than Bayesian methods (for instance by using minimax decision rules such as the maximum-entropy example given later). Note also that many frequentist methods do correspond to a Bayesian method for some appropriately chosen prior. But the crucial point is that the frequentist told me how to pick a prior I would be happy with (also, many frequentist methods don’t correspond to a Bayesian method for any choice of prior; they nevertheless often perform quite well).
Myth 2: Bayesian methods are optimal except for computational considerations. We already covered this in the previous point under the complete class theorem, but to re-iterate: Bayesian methods are locally optimal, not global optimal. Identifying all the local optima is very different from knowing which of them is the global optimum. I would much rather have someone hand me something that wasn’t a local optimum but was close to the global optimum, than something that was a local optimum but was far from the global optimum.
Myth 3: We can deal with computational constraints simply by making approximations to Bayes. I have rarely seen this born out in practice. Here’s a challenge: suppose I give you data generated in the following way. There are a collection of vectors  ,
,  ,
,  ,
,  , each with
, each with  coordinates. I generate outputs
coordinates. I generate outputs  ,
,  , ,
, ,  in the following way. First I globally select
in the following way. First I globally select  of the coordinates uniformly at random, then I select a fixed vector
of the coordinates uniformly at random, then I select a fixed vector  such that those coordinates are drawn from i.i.d. Gaussians and the rest of the coordinates are zero. Now I set
such that those coordinates are drawn from i.i.d. Gaussians and the rest of the coordinates are zero. Now I set  (i.e.
(i.e.  is the dot product of with
is the dot product of with  ). You are given
). You are given  and
and  , and your job is to infer . This is a completely well-specified problem, the only task remaining is computational. I know people who have solved this problem using Bayesan methods with approximate inference. I have respect for these people, because doing so is no easy task. I think very few of them would say that “we can just approximate Bayesian updating and be fine”. (Also, this particular problem can be solved trivially with frequentist methods.)
, and your job is to infer . This is a completely well-specified problem, the only task remaining is computational. I know people who have solved this problem using Bayesan methods with approximate inference. I have respect for these people, because doing so is no easy task. I think very few of them would say that “we can just approximate Bayesian updating and be fine”. (Also, this particular problem can be solved trivially with frequentist methods.)
A particularly egregious example of this is when people talk about “computable approximations to Solomonoff induction” or “computable approximations to AIXI” as if such notions were meaningful.
Myth 4: the prior isn’t a big deal because Bayesians can always share likelihood ratios. Putting aside the practical issue that there would in general be an infinite number of likelihood ratios to share, there is the larger issue that for any hypothesis  , there is also the hypothesis
, there is also the hypothesis  that matches exactly up to now, and then predicts the opposite of at all points in the future. You have to constrain model complexity at some point, the question is about how. To put this another way, sharing my likelihood ratios without also constraining model complexity (by focusing on a subset of all logically possible hypotheses) would be equivalent to just sharing all sensory data I’ve ever accrued in my life. To the extent that such a notion is even possible, I certainly don’t need to be a Bayesian to do such a thing.
that matches exactly up to now, and then predicts the opposite of at all points in the future. You have to constrain model complexity at some point, the question is about how. To put this another way, sharing my likelihood ratios without also constraining model complexity (by focusing on a subset of all logically possible hypotheses) would be equivalent to just sharing all sensory data I’ve ever accrued in my life. To the extent that such a notion is even possible, I certainly don’t need to be a Bayesian to do such a thing.
Myth 5: frequentist methods need to assume their model is correct or that the data are i.i.d. Understanding the content of this section is the most important single insight to gain from this essay. For some reason it’s assumed that frequentist methods need to make strong assumptions (such as Gaussianity), whereas Bayesian methods are somehow immune to this. In reality, the opposite is true. While there are many beautiful and deep frequentist formalisms that answer this, I will choose to focus on one of my favorite, which is online learning.
To explain the online learning framework, let us suppose that our data are , (x_2, y_2), \ldots, (x_T, y_T)}") . We don’t observe
. We don’t observe  until after making a prediction
until after making a prediction  of what will be, and then we receive a penalty
of what will be, and then we receive a penalty }") based on how incorrect we were. So we can think of this as receiving prediction problems one-by-one, and in particular we make no assumptions about the relationship between the different problems; they could be i.i.d., they could be positively correlated, they could be anti-correlated, they could even be adversarially chosen.
based on how incorrect we were. So we can think of this as receiving prediction problems one-by-one, and in particular we make no assumptions about the relationship between the different problems; they could be i.i.d., they could be positively correlated, they could be anti-correlated, they could even be adversarially chosen.
As a running example, suppose that I’m betting on horses and before each race there are  other people who give me advice on which horse to bet on. I know nothing about horses, so based on this advice I’d like to devise a good betting strategy. In this case,
other people who give me advice on which horse to bet on. I know nothing about horses, so based on this advice I’d like to devise a good betting strategy. In this case,  would be the bets that each of the other people recommend, would be the horse that I actually bet on, and would be the horse that actually wins the race. Then, supposing that
would be the bets that each of the other people recommend, would be the horse that I actually bet on, and would be the horse that actually wins the race. Then, supposing that  (i.e., the horse I bet on actually wins), is the negative of the payoff from correctly betting on that horse. Otherwise, if the horse I bet on doesn’t win, is the cost I had to pay to place the bet.
(i.e., the horse I bet on actually wins), is the negative of the payoff from correctly betting on that horse. Otherwise, if the horse I bet on doesn’t win, is the cost I had to pay to place the bet.
If I’m in this setting, what guarantee can I hope for? I might ask for an algorithm that is guaranteed to make good bets — but this seems impossible unless the people advising me actually know something about horses. Or, at the very least, one of the people advising me knows something. Motivated by this, I define my regret to be the difference between my penalty and the penalty of the best of the people (note that I only have access to the latter after all  rounds of betting). More formally, given a class
rounds of betting). More formally, given a class  of predictors
of predictors  , I define
, I define
 = \frac{1}{T} \sum_{t=1}^T L(y_t, z_t) - \min_{h \in \mathcal{M}} \frac{1}{T} \sum_{t=1}^T L(y_t, h(x_t))")
In this case, would have size and the  th predictor would just always follow the advice of person . The regret is then how much worse I do on average than the best expert. A remarkable fact is that, in this case, there is a strategy such that
th predictor would just always follow the advice of person . The regret is then how much worse I do on average than the best expert. A remarkable fact is that, in this case, there is a strategy such that }") shrinks at a rate of
shrinks at a rate of }{T}}}") . In other words, I can have an average score within
. In other words, I can have an average score within  of the best advisor after
of the best advisor after }{\epsilon^2}}") rounds of betting.
rounds of betting.
One reason that this is remarkable is that it does not depend at all on how the data are distributed; the data could be i.i.d., positively correlated, negatively correlated, even adversarial, and one can still construct an (adaptive) prediction rule that does almost as well as the best predictor in the family.
To be even more concrete, if we assume that all costs and payoffs are bounded by  per round, and that there are
per round, and that there are  people in total, then an explicit upper bound is that after
people in total, then an explicit upper bound is that after  rounds, we will be within dollars on average of the best other person. Under slightly stronger assumptions, we can do even better, for instance if the best person has an average variance of
rounds, we will be within dollars on average of the best other person. Under slightly stronger assumptions, we can do even better, for instance if the best person has an average variance of  about their mean, then the
about their mean, then the  can be replaced with
can be replaced with  .
.
It is important to note that the betting scenario is just a running example, and one can still obtain regret bounds under fairly general scenarios; could be continuous and  could have quite general structure; the only technical assumption is that be a convex set and that be a convex function of
could have quite general structure; the only technical assumption is that be a convex set and that be a convex function of  . These assumptions tend to be easy to satisfy, though I have run into a few situations where they end up being problematic, mainly for computational reasons. For an -dimensional model family, typically decreases at a rate of
. These assumptions tend to be easy to satisfy, though I have run into a few situations where they end up being problematic, mainly for computational reasons. For an -dimensional model family, typically decreases at a rate of  , although under additional assumptions this can be reduced to , as in the betting example above. I would consider this reduction to be one of the crowning results of modern frequentist statistics.
, although under additional assumptions this can be reduced to , as in the betting example above. I would consider this reduction to be one of the crowning results of modern frequentist statistics.
Yes, these guarantees sound incredibly awesome and perhaps too good to be true. They actually are that awesome, and they are actually true. The work is being done by measuring the error relative to the best model in the model family. We aren’t required to do well in an absolute sense, we just need to not do any worse than the best model. Of as long as at least one of the models in our family makes good predictions, that means we will as well. This is really what statistics is meant to be doing: you come up with everything you imagine could possibly be reasonable, and hand it to me, and then I come up with an algorithm that will figure out which of the things you handed me was most reasonable, and will do almost as well as that. As long as at least one of the things you come up with is good, then my algorithm will do well. Importantly, due to the }") dependence on the dimension of the model family, you can actually write down extremely broad classes of models and I will still successfully sift through them.
dependence on the dimension of the model family, you can actually write down extremely broad classes of models and I will still successfully sift through them.
Let me stress again: regret bounds are saying that, no matter how the and are related, no i.i.d. assumptions anywhere in sight, we will do almost as well as any predictor in (in particular, almost as well as the best predictor).
Myth 6: frequentist methods can only deal with simple models and need to make arbitrary cutoffs in model complexity. A naive perusal of the literature might lead one to believe that frequentists only ever consider very simple models, because many discussions center on linear and log-linear models. To dispel this, I will first note that there are just as many discussions that focus on much more general properties such as convexity and smoothness, and that can achieve comparably good bounds in many cases. But more importantly, the reason we focus so much on linear models is because we have already reduced a large family of problems to (log-)linear regression. The key insight, and I think one of the most important insights in all of applied mathematics, is that of featurization: given a non-linear problem, we can often embed it into a higher-dimensional linear problem, via a feature map  (
( denotes -dimensional space, i.e. vectors of real numbers of length ). For instance, if I think that is a polynomial (say cubic) function of , I can apply the mapping
denotes -dimensional space, i.e. vectors of real numbers of length ). For instance, if I think that is a polynomial (say cubic) function of , I can apply the mapping  = (1, x, x^2, x^3)}") , and now look for a linear relationship between and
, and now look for a linear relationship between and }") .
.
This insight extends far beyond polynomials. In combinatorial domains such as natural language, it is common to use indicator features: features that are  if a certain event occurs and
if a certain event occurs and  otherwise. For instance, I might have an indicator feature for whether two words appear consecutively in a sentence, whether two parts of speech are adjacent in a syntax tree, or for what part of speech a word has. Almost all state of the art systems in natural language processing work by solving a relatively simple regression task (typically either log-linear or max-margin) over a rich feature space (often involving hundreds of thousands or millions of features, i.e. an embedding into
otherwise. For instance, I might have an indicator feature for whether two words appear consecutively in a sentence, whether two parts of speech are adjacent in a syntax tree, or for what part of speech a word has. Almost all state of the art systems in natural language processing work by solving a relatively simple regression task (typically either log-linear or max-margin) over a rich feature space (often involving hundreds of thousands or millions of features, i.e. an embedding into  or
or  ).
).
A counter-argument to the previous point could be: “Sure, you could create a high-dimensional family of models, but it’s still a parameterized family. I don’t want to be stuck with a parameterized family, I want my family to include all Turing machines!” Putting aside for a second the question of whether “all Turing machines” is a well-advised model choice, this is something that a frequentist approach can handle just fine, using a tool called regularization, which after featurization is the second most important idea in statistics.
Specifically, given any sufficiently quickly growing function }") , one can show that, given data points, there is a strategy whose average error is at most
, one can show that, given data points, there is a strategy whose average error is at most }{T}}}") worse than any estimator . This can hold even if the model class is infinite dimensional. For instance, if consists of all probability distributions over Turing machines, and we let
worse than any estimator . This can hold even if the model class is infinite dimensional. For instance, if consists of all probability distributions over Turing machines, and we let  denote the probability mass placed on the th Turing machine, then a valid regularizer
denote the probability mass placed on the th Turing machine, then a valid regularizer  would be
would be
 = \sum_i h_i \log(i^2 \cdot h_i)")
If we consider this, then we see that, for any probability distribution over the first  Turing machines (i.e. all Turing machines with description length
Turing machines (i.e. all Turing machines with description length  ), the value of is at most
), the value of is at most ^2) = k\log(4)}") . (Here we use the fact that
. (Here we use the fact that  \geq \sum_i h_i \log(i^2)}") , since
, since  and hence
and hence  \leq 0}") .) This means that, if we receive roughly
.) This means that, if we receive roughly  data, we will achieve error within of the best Turing machine that has description length .
data, we will achieve error within of the best Turing machine that has description length .
Let me note several things here:
- This strategy makes no assumptions about the data being i.i.d. It doesn’t even assume that the data are computable. It just guarantees that it will perform as well as any Turing machine (or distribution over Turing machines) given the appropriate amount of data.
- This guarantee holds for any given sufficiently smooth measurement of prediction error (the update strategy depends on the particular error measure).
- This guarantee holds deterministically, no randomness required (although predictions may need to consist of probability distributions rather than specific points, but this is also true of Bayesian predictions).
Interestingly, in the case that the prediction error is given by the negative log probability assigned to the truth, then the corresponding strategy that achieves the error bound is just normal Bayesian updating. But for other measurements of error, we get different update strategies. Although I haven’t worked out the math, intuitively this difference could be important if the universe is fundamentally unpredictable but our notion of error is insensitive to the unpredictable aspects.
Myth 7: frequentist methods hide their assumptions while Bayesian methods make assumptions explicit. I’m still not really sure where this came from. As we’ve seen numerous times so far, a very common flavor among frequentist methods is the following: I have a model class , I want to do as well as any model in ; or put another way:
Assumption: At least one model in has error at most  .
.
Guarantee: My method will have error at most  .
.
This seems like a very explicit assumption with a very explicit guarantee. On the other hand, an argument I hear is that Bayesian methods make their assumptions explicit because they have an explicit prior. If I were to write this as an assumption and guarantee, I would write:
Assumption: The data were generated from the prior.
Guarantee: I will perform at least as well as any other method.
While I agree that this is an assumption and guarantee of Bayesian methods, there are two problems that I have with drawing the conclusion that “Bayesian methods make their assumptions explicit”. The first is that it can often be very difficult to understand how a prior behaves; so while we could say “The data were generated from the prior” is an explicit assumption, it may be unclear what exactly that assumption entails. However, a bigger issue is that “The data were generated from the prior” is an assumption that very rarely holds; indeed, in many cases the underlying process is deterministic (if you’re a subjective Bayesian then this isn’t necessarily a problem, but it does certainly mean that the assumption given above doesn’t hold). So given that that assumption doesn’t hold but Bayesian methods still often perform well in practice, I would say that Bayesian methods are making some other sort of “assumption” that is far less explicit (indeed, I would be very interested in understanding what this other, more nebulous assumption might be).
Myth 8: frequentist methods are fragile, Bayesian methods are robust. This is another one that’s straightforwardly false. First, since frequentist methods often rest on weaker assumptions they are more robust if the assumptions don’t quite hold. Secondly, there is an entire area of robust statistics, which focuses on being robust to adversarial errors in the problem data.
Myth 9: frequentist methods are responsible for bad science. I will concede that much bad science is done using frequentist statistics. But this is true only because pretty much all science is done using frequentist statistics. I’ve heard arguments that using Bayesian methods instead of frequentist methods would fix at least some of the problems with science. I don’t think this is particularly likely, as I think many of the problems come from mis-application of statistical tools or from failure to control for multiple hypotheses. If anything, Bayesian methods would exacerbate the former, because they often require more detailed modeling (although in most simple cases the difference doesn’t matter at all). I don’t think being Bayesian guards against multiple hypothesis testing. Yes, in some sense a prior “controls for multiple hypotheses”, but in general the issue is that the “multiple hypotheses” are never written down in the first place, or are written down and then discarded. One could argue that being in the habit of writing down a prior might make practitioners more likely to think about multiple hypotheses, but I’m not sure this is the first-order thing to worry about.
Myth 10: frequentist methods are unprincipled / hacky. One of the most beautiful theoretical paradigms that I can think of is what I could call the “geometric view of statistics”. One place that does a particularly good job of show-casing this is Shai Shalev-Shwartz’s PhD thesis, which was so beautiful that I cried when I read it. I’ll try (probably futilely) to convey a tiny amount of the intuition and beauty of this paradigm in the next few paragraphs, although focusing on minimax estimation, rather than online learning as in Shai’s thesis.
The geometric paradigm tends to emphasize a view of measurements (i.e. empirical expected values over observed data) as “noisy” linear constraints on a model family. We can control the noise by either taking few enough measurements that the total error from the noise is small (classical statistics), or by broadening the linear constraints to convex constraints (robust statistics), or by controlling the Lagrange multipliers on the constraints (regularization). One particularly beautiful result in this vein is the duality between maximum entropy and maximum likelihood. (I can already predict the Jaynesians trying to claim this result for their camp, but (i) Jaynes did not invent maximum entropy; (ii) maximum entropy is not particularly Bayesian (in the sense that frequentists use it as well); and (iii) the view on maximum entropy that I’m about to provide is different from the view given in Jaynes or by physicists in general [edit: EHeller thinks this last claim is questionable, see discussion here].)
To understand the duality mentioned above, suppose that we have a probability distribution }") and the only information we have about it is the expected value of a certain number of functions, i.e. the information that
and the only information we have about it is the expected value of a certain number of functions, i.e. the information that ![{\mathbb{E}[\phi(x)] = \phi^*}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B%5Cphi%28x%29%5D+%3D+%5Cphi%5E%2A%7D&bg=f0f0f0&fg=000000&s=0 "{\mathbb{E}[\phi(x)] = \phi^*}") , where the expectation is taken with respect to . We are interested in constructing a probability distribution
, where the expectation is taken with respect to . We are interested in constructing a probability distribution }") such that no matter what particular value takes, will still make good predictions. In other words (taking
such that no matter what particular value takes, will still make good predictions. In other words (taking }") as our measurement of prediction accuracy) we want
as our measurement of prediction accuracy) we want ![{\mathbb{E}_{p'}[\log q(x)]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bp%27%7D%5B%5Clog+q%28x%29%5D%7D&bg=f0f0f0&fg=000000&s=0 "{\mathbb{E}_{p'}[\log q(x)]}") to be large for all distributions
to be large for all distributions  such that
such that ![{\mathbb{E}_{p'}[\phi(x)] = \phi^*}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bp%27%7D%5B%5Cphi%28x%29%5D+%3D+%5Cphi%5E%2A%7D&bg=f0f0f0&fg=000000&s=0 "{\mathbb{E}_{p'}[\phi(x)] = \phi^*}") . Using a technique called Lagrangian duality, we can both find the optimal distribution
. Using a technique called Lagrangian duality, we can both find the optimal distribution  and compute its worse-case accuracy over all with . The characterization is as follows: consider all probability distributions that are proportional to
and compute its worse-case accuracy over all with . The characterization is as follows: consider all probability distributions that are proportional to )}") for some vector
for some vector  , i.e.
, i.e.  = \exp(\lambda^{\top}\phi(x))/Z(\lambda)}") for some
for some }") . Of all of these, take the q(x) with the largest value of
. Of all of these, take the q(x) with the largest value of }") . Then will be the optimal distribution and the accuracy for all distributions will be exactly . Furthermore, if
. Then will be the optimal distribution and the accuracy for all distributions will be exactly . Furthermore, if  is the empirical expectation given some number of samples, then one can show that is propotional to the log likelihood of , which is why I say that maximum entropy and maximum likelihood are dual to each other.
is the empirical expectation given some number of samples, then one can show that is propotional to the log likelihood of , which is why I say that maximum entropy and maximum likelihood are dual to each other.
This is a relatively simple result but it underlies a decent chunk of models used in practice.
Myth 11: frequentist methods have no promising approach to computationally bounded inference. I would personally argue that frequentist methods are more promising than Bayesian methods at handling computational constraints, although computationally bounded inference is a very cutting edge area and I’m sure other experts would disagree. However, one point in favor of the frequentist approach here is that we already have some frameworks, such as the “tightening relaxations” framework discussed here, that provide quite elegant and rigorous ways of handling computationally intractable models.
References
(Myth 3) Sparse recovery: Sparse recovery using sparse matrices
(Myth 5) Online learning: Online learning and online convex optimization
(Myth 8) Robust statistics: see this blog post and the two linked papers
(Myth 10) Maximum entropy duality: Game theory, maximum entropy, minimum discrepancy and robust Bayesian decision theory
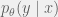











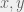


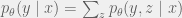
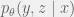
. Call the result
.
as being distributed according to
. On a new value
for which
as being distributed according to
.
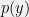 on a space
on a space  . Suppose we want to construct a set
. Suppose we want to construct a set 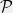 of probability distributions on
of probability distributions on 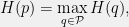
![{H(p) = \mathbb{E}_{p}[-\log p(y)]}](https://s0.wp.com/latex.php?latex=%7BH%28p%29+%3D+%5Cmathbb%7BE%7D_%7Bp%7D%5B-%5Clog+p%28y%29%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) is the entropy. We call such a set a maximum-entropy set for
is the entropy. We call such a set a maximum-entropy set for  . Furthermore, we would like
. Furthermore, we would like 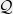 satisfying the same property,
satisfying the same property,  ? It turns out that the answer is yes, and there is even a simple characterization of
? It turns out that the answer is yes, and there is even a simple characterization of ![\displaystyle \mathcal{P} = \{q \mid \mathbb{E}_{q}[-\log p(y)] \leq H(p)\}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BP%7D+%3D+%5C%7Bq+%5Cmid+%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D+%5Cleq+H%28p%29%5C%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)
 , and for any
, and for any  we have
we have![\displaystyle \begin{array}{rcl} H(q) &=& \mathbb{E}_{q}[-\log q(y)] \\ &\leq& \mathbb{E}_{q}[-\log p(y)] \\ &\leq& H(p), \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+H%28q%29+%26%3D%26+%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+q%28y%29%5D+%5C%5C+%26%5Cleq%26+%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D+%5C%5C+%26%5Cleq%26+H%28p%29%2C+%5Cend%7Barray%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)
 , we must have
, we must have  . Let us suppose for the sake of contradiction that
. Let us suppose for the sake of contradiction that 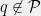 , so that
, so that ![{\mathbb{E}_{q}[-\log p(y)] > H(p)}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D+%3E+H%28p%29%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) . Then we have
. Then we have![\displaystyle \begin{array}{rcl} H((1-\epsilon)p + \epsilon q) &=& \mathbb{E}_{(1-\epsilon)p+\epsilon q}[-\log((1-\epsilon)p(y)+\epsilon q(y))] \\ &=& \mathbb{E}_{(1-\epsilon)p+\epsilon q}[-\log(p(y) + \epsilon (q(y)-p(y))] \\ &=& \mathbb{E}_{(1-\epsilon)p+\epsilon q}\left[-\log(p(y)) - \epsilon \frac{q(y)-p(y)}{p(y)} + \mathcal{O}(\epsilon^2)\right] \\ &=& H(p) + \epsilon(\mathbb{E}_{q}[-\log p(y)]-H(p)) - \epsilon \mathbb{E}_{(1-\epsilon)p+\epsilon q}\left[\frac{q(y)-p(y)}{p(y)}\right] + \mathcal{O}(\epsilon^2) \\ &=& H(p) + \epsilon(\mathbb{E}_{q}[-\log p(y)]-H(p)) - \epsilon^2 \mathbb{E}_{q}\left[\frac{q(y)-p(y)}{p(y)}\right] + \mathcal{O}(\epsilon^2) \\ &=& H(p) + \epsilon(\mathbb{E}_{q}[-\log p(y)]-H(p)) + \mathcal{O}(\epsilon^2). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+H%28%281-%5Cepsilon%29p+%2B+%5Cepsilon+q%29+%26%3D%26+%5Cmathbb%7BE%7D_%7B%281-%5Cepsilon%29p%2B%5Cepsilon+q%7D%5B-%5Clog%28%281-%5Cepsilon%29p%28y%29%2B%5Cepsilon+q%28y%29%29%5D+%5C%5C+%26%3D%26+%5Cmathbb%7BE%7D_%7B%281-%5Cepsilon%29p%2B%5Cepsilon+q%7D%5B-%5Clog%28p%28y%29+%2B+%5Cepsilon+%28q%28y%29-p%28y%29%29%5D+%5C%5C+%26%3D%26+%5Cmathbb%7BE%7D_%7B%281-%5Cepsilon%29p%2B%5Cepsilon+q%7D%5Cleft%5B-%5Clog%28p%28y%29%29+-+%5Cepsilon+%5Cfrac%7Bq%28y%29-p%28y%29%7D%7Bp%28y%29%7D+%2B+%5Cmathcal%7BO%7D%28%5Cepsilon%5E2%29%5Cright%5D+%5C%5C+%26%3D%26+H%28p%29+%2B+%5Cepsilon%28%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D-H%28p%29%29+-+%5Cepsilon+%5Cmathbb%7BE%7D_%7B%281-%5Cepsilon%29p%2B%5Cepsilon+q%7D%5Cleft%5B%5Cfrac%7Bq%28y%29-p%28y%29%7D%7Bp%28y%29%7D%5Cright%5D+%2B+%5Cmathcal%7BO%7D%28%5Cepsilon%5E2%29+%5C%5C+%26%3D%26+H%28p%29+%2B+%5Cepsilon%28%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D-H%28p%29%29+-+%5Cepsilon%5E2+%5Cmathbb%7BE%7D_%7Bq%7D%5Cleft%5B%5Cfrac%7Bq%28y%29-p%28y%29%7D%7Bp%28y%29%7D%5Cright%5D+%2B+%5Cmathcal%7BO%7D%28%5Cepsilon%5E2%29+%5C%5C+%26%3D%26+H%28p%29+%2B+%5Cepsilon%28%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D-H%28p%29%29+%2B+%5Cmathcal%7BO%7D%28%5Cepsilon%5E2%29.+%5Cend%7Barray%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)
![{\mathbb{E}_{q}[-\log p(y)] - H(p) > 0}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7Bq%7D%5B-%5Clog+p%28y%29%5D+-+H%28p%29+%3E+0%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) , for sufficiently small
, for sufficiently small  this will exceed
this will exceed 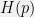 , which is a contradiction. Therefore we must have
, which is a contradiction. Therefore we must have  is said to be strongly convex with respect to a norm
is said to be strongly convex with respect to a norm  if
if
 . So, under what conditions does this hold?
. So, under what conditions does this hold?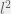 norm, the answer is easy:
norm, the answer is easy:  if and only if
if and only if  (i.e.,
(i.e.,  is positive semidefinite). This can be shown in many ways, perhaps the easiest is by noting that
is positive semidefinite). This can be shown in many ways, perhaps the easiest is by noting that  .
. norm, the answer is a bit trickier but still not too complicated. Recall that we want necessary and sufficient conditions under which
norm, the answer is a bit trickier but still not too complicated. Recall that we want necessary and sufficient conditions under which 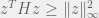 . Note that this is equivalent to asking that
. Note that this is equivalent to asking that 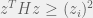 for each coordinate
for each coordinate  of
of 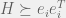 for each coordinate vector
for each coordinate vector  (these are the vectors that are 1 in the
(these are the vectors that are 1 in the  which satisfies, among other properties, the relationship
which satisfies, among other properties, the relationship  . So, in general,
. So, in general,  for all
for all  with
with  . But this is in turn equivalent to asking that
. But this is in turn equivalent to asking that for all
for all  ; this is why we were able to obtain such a clean formulation in the
; this is why we were able to obtain such a clean formulation in the  , whose unit ball is the simplex, which is a polytope with only
, whose unit ball is the simplex, which is a polytope with only 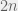 vertices (namely, each of the signed unit vectors
vertices (namely, each of the signed unit vectors  ).
). -dimensional hypercube, with vertices given by all
-dimensional hypercube, with vertices given by all 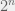 vectors of the form
vectors of the form ![[ \pm 1 \ \cdots \ \pm 1]](https://s0.wp.com/latex.php?latex=%5B+%5Cpm+1+%5C+%5Ccdots+%5C+%5Cpm+1%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) . Thus
. Thus 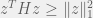 if and only if
if and only if  for all
for all  .
. . We thus have the general criterion:
. We thus have the general criterion: for
for  if and only if
if and only if 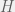 is strongly convex with respect to the norm
is strongly convex with respect to the norm  ,
,  , where
, where 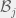 is the
is the  .
.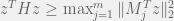 . Now note that
. Now note that  . If we define
. If we define  , it is then apparent that the dual norm unit ball is the convex hull of the
, it is then apparent that the dual norm unit ball is the convex hull of the  that is jointly convex in any
that is jointly convex in any  of the variables, but not in all variables at once. The function is
of the variables, but not in all variables at once. The function is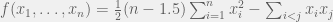
![\left[ \begin{array}{cccc} n-1.5 & -1 & \cdots & -1 \\ -1 & n-1.5 & \cdots & -1 \\ \vdots & \vdots & \ddots & \vdots \\ -1 & -1 & \cdots & n-1.5 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+n-1.5+%26+-1+%26+%5Ccdots+%26+-1+%5C%5C+-1+%26+n-1.5+%26+%5Ccdots+%26+-1+%5C%5C+%5Cvdots+%26+%5Cvdots+%26+%5Cddots+%26+%5Cvdots+%5C%5C+-1+%26+-1+%26+%5Ccdots+%26+n-1.5+%5Cend%7Barray%7D+%5Cright%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)
 , where
, where  is the identity matrix and
is the identity matrix and  is the all-ones matrix, which is rank 1 and whose single non-zero eigenvalue is
is the all-ones matrix, which is rank 1 and whose single non-zero eigenvalue is  , as well as a single eigenvalue of
, as well as a single eigenvalue of 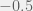 , and hence is not positive definite.
, and hence is not positive definite. , but where now
, but where now  . This matrix now has
. This matrix now has  eigenvalues of
eigenvalues of  , and hence is positive definite. Therefore, the Hessian is positive definite when restricted to any
, and hence is positive definite. Therefore, the Hessian is positive definite when restricted to any  samples for the left and right subtrees, then look at all
samples for the left and right subtrees, then look at all 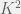 ways of combining them into the entire tree, but then downsample again to the
ways of combining them into the entire tree, but then downsample again to the  , then our particles will be sets obtained by specifying the values of some of the
, then our particles will be sets obtained by specifying the values of some of the 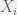 and leaving the rest to vary arbitrarily. So, for instance, if
and leaving the rest to vary arbitrarily. So, for instance, if  , then
, then  might be a possible “fat” particle.
might be a possible “fat” particle.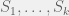 , and we assign probability
, and we assign probability  to
to 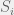 , then we have the polytope of distributions
, then we have the polytope of distributions 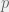 that satisfy the constraints
that satisfy the constraints  , etc.
, etc. particles, then the product distribution has
particles, then the product distribution has  particles — this could be problematic computationally, so we also want a way to narrow down to a subset of the
particles — this could be problematic computationally, so we also want a way to narrow down to a subset of the  and want to apply a function
and want to apply a function  to it. If
to it. If 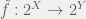 such that
such that  for all
for all  . In this case, if we map a particle
. In this case, if we map a particle  to
to  , our equality constraint on the mass assigned to
, our equality constraint on the mass assigned to 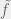 (when combined with conditioning on data, which is discussed below) allows us to assign partial credit to promising particles, which was the other property I discussed at the beginning.
(when combined with conditioning on data, which is discussed below) allows us to assign partial credit to promising particles, which was the other property I discussed at the beginning.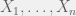 are independent, then their sum has a distribution that decays like
are independent, then their sum has a distribution that decays like 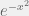 . For random variables that are only pairwise independent, the strongest bound we have is Chebyshev’s inequality, which says that their sum decays like
. For random variables that are only pairwise independent, the strongest bound we have is Chebyshev’s inequality, which says that their sum decays like  .
. be independent binary random variables, and for any
be independent binary random variables, and for any  , let
, let 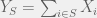 , where the sum is taken mod 2. Then we can easily check that the
, where the sum is taken mod 2. Then we can easily check that the  are pairwise independent. Now consider the random variable
are pairwise independent. Now consider the random variable  . If any of the
. If any of the  in this case. On the other hand, if all of the
in this case. On the other hand, if all of the  as well. Thus, with probability
as well. Thus, with probability  ,
,  deviates from its mean by
deviates from its mean by  , whereas the variance of
, whereas the variance of  . The bound on this probability form Chebyshev is
. The bound on this probability form Chebyshev is  , which is very close to
, which is very close to  , the KL divergence is defined as
, the KL divergence is defined as
 . Intuitively, a small KL(p || q) means that there are few points that p assigns high probability to but that q does not. We can also think of KL(p || q) as the number of bits of information needed to update from the distribution q to the distribution p.
. Intuitively, a small KL(p || q) means that there are few points that p assigns high probability to but that q does not. We can also think of KL(p || q) as the number of bits of information needed to update from the distribution q to the distribution p. and
and  . Can we bound
. Can we bound  in terms of the
in terms of the  ? In some sense this is asking to upper bound the KL divergence in terms of some more local KL divergence. It turns out this can be done:
? In some sense this is asking to upper bound the KL divergence in terms of some more local KL divergence. It turns out this can be done: and
and  and
and 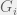 are all probability distributions, then
are all probability distributions, then .
.
 , re-write the condition for a given value of
, re-write the condition for a given value of 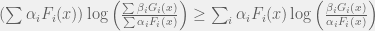
 function:
function: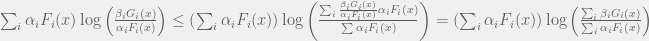

 in terms of
in terms of  , it is enough to first locate the
, it is enough to first locate the  , it also says that the KL divergence between two different mixtures of the same set of distributions is at most the KL divergence between the mixture weights.
, it also says that the KL divergence between two different mixtures of the same set of distributions is at most the KL divergence between the mixture weights. , of the form
, of the form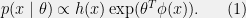

 . Note that we can re-write the right-hand-side of (
. Note that we can re-write the right-hand-side of (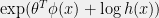 , so an exponential family is really just a log-linear model with one of the coordinates of
, so an exponential family is really just a log-linear model with one of the coordinates of  constrained to equal
constrained to equal  . Also note that the normalization constant in (
. Also note that the normalization constant in ( ), so we can express (
), so we can express (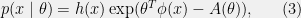
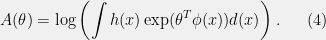
![{\phi(x) = \left[ \begin{array}{c} x \\ x^2\end{array} \right]}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%28x%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+x%5E2%5Cend%7Barray%7D+%5Cright%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) . Then
. Then  . If we let
. If we let ![{\theta = \left[\frac{\mu}{\sigma^2},-\frac{1}{2\sigma^2}\right]}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta+%3D+%5Cleft%5B%5Cfrac%7B%5Cmu%7D%7B%5Csigma%5E2%7D%2C-%5Cfrac%7B1%7D%7B2%5Csigma%5E2%7D%5Cright%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) , then
, then  . We therefore see that Gaussian distributions are an exponential family for
. We therefore see that Gaussian distributions are an exponential family for ![{\phi(x) = \left[ \begin{array}{c} x \\ x^2 \end{array} \right]}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%28x%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+x%5E2+%5Cend%7Barray%7D+%5Cright%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) .
.![{\phi(x) = [x]}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%28x%29+%3D+%5Bx%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) and
and  . Then
. Then  . If we let
. If we let 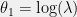 then we get
then we get 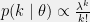 ; we thus see that Poisson distributions are also an exponential family.
; we thus see that Poisson distributions are also an exponential family.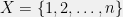 . Let
. Let  be an
be an 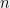 -dimensional vector whose
-dimensional vector whose 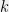 th element is
th element is  . If
. If 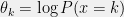 , then we obtain an arbitrary multinomial distribution. Therefore, multinomial distributions are also an exponential family.
, then we obtain an arbitrary multinomial distribution. Therefore, multinomial distributions are also an exponential family. is any deterministic function of that variable. For instance, if
is any deterministic function of that variable. For instance, if ![{X = [X_1,\ldots,X_n]^T}](https://s0.wp.com/latex.php?latex=%7BX+%3D+%5BX_1%2C%5Cldots%2CX_n%5D%5ET%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) is a vector of Gaussian random variables, then the sample mean
is a vector of Gaussian random variables, then the sample mean  and sample variance
and sample variance  are both statistics.
are both statistics. be a family of distributions parameterized by
be a family of distributions parameterized by  . Then a vector
. Then a vector 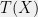 of statistics are called sufficient statistics for
of statistics are called sufficient statistics for 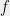 , we have
, we have![\displaystyle \mathbb{E}[f(X) \mid T(X) = T_0, \theta = \theta_0] = S(f,T_0), \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5Bf%28X%29+%5Cmid+T%28X%29+%3D+T_0%2C+%5Ctheta+%3D+%5Ctheta_0%5D+%3D+S%28f%2CT_0%29%2C+%5C+%5C+%5C+%5C+%5C+%285%29&bg=f0f0f0&fg=000000&s=0&c=20201002)
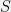 that has no dependence on
that has no dependence on  with unknown mean
with unknown mean 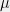 and variance
and variance  . It turns out that
. It turns out that ![{T(X) := [\hat{\mu},\hat{\sigma}^2]}](https://s0.wp.com/latex.php?latex=%7BT%28X%29+%3A%3D+%5B%5Chat%7B%5Cmu%7D%2C%5Chat%7B%5Csigma%7D%5E2%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) is a sufficient statistic for
is a sufficient statistic for  . Then the statistics
. Then the statistics 
![\displaystyle \begin{array}{rcl} \mathbb{E}[f(X) \mid T(X) = T_0, \theta = \theta_0] &=& \frac{\int_{T(X) = T_0} f(X) dp(X \mid \theta=\theta_0)}{\int_{T(X) = T_0} dp(X \mid \theta=\theta_0)}\\ \\ &=& \frac{\int_{T(X)=T_0} f(X)h(X)g_\theta(T_0) dX}{\int_{T(X)=T_0} h(X)g_\theta(T_0) dX}\\ \\ &=& \frac{\int_{T(X)=T_0} f(X)h(X)dX}{\int_{T(X)=T_0} h(X) dX}, \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cmathbb%7BE%7D%5Bf%28X%29+%5Cmid+T%28X%29+%3D+T_0%2C+%5Ctheta+%3D+%5Ctheta_0%5D+%26%3D%26+%5Cfrac%7B%5Cint_%7BT%28X%29+%3D+T_0%7D+f%28X%29+dp%28X+%5Cmid+%5Ctheta%3D%5Ctheta_0%29%7D%7B%5Cint_%7BT%28X%29+%3D+T_0%7D+dp%28X+%5Cmid+%5Ctheta%3D%5Ctheta_0%29%7D%5C%5C+%5C%5C+%26%3D%26+%5Cfrac%7B%5Cint_%7BT%28X%29%3DT_0%7D+f%28X%29h%28X%29g_%5Ctheta%28T_0%29+dX%7D%7B%5Cint_%7BT%28X%29%3DT_0%7D+h%28X%29g_%5Ctheta%28T_0%29+dX%7D%5C%5C+%5C%5C+%26%3D%26+%5Cfrac%7B%5Cint_%7BT%28X%29%3DT_0%7D+f%28X%29h%28X%29dX%7D%7B%5Cint_%7BT%28X%29%3DT_0%7D+h%28X%29+dX%7D%2C+%5Cend%7Barray%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)
![{\mathbb{E}[f(X) \mid T(X) = T_0, \theta = \theta_0]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5Bf%28X%29+%5Cmid+T%28X%29+%3D+T_0%2C+%5Ctheta+%3D+%5Ctheta_0%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) for an arbitrary density
for an arbitrary density 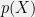 , we get
, we get![\displaystyle \begin{array}{rcl} \mathbb{E}[f(X) \mid T(X) = T_0, \theta = \theta_0] &=& \int_{T(X) = T_0} f(X) \frac{p(X \mid \theta=\theta_0)}{\int_{T(X)=T_0} p(X \mid \theta=\theta_0) dX} dX. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cmathbb%7BE%7D%5Bf%28X%29+%5Cmid+T%28X%29+%3D+T_0%2C+%5Ctheta+%3D+%5Ctheta_0%5D+%26%3D%26+%5Cint_%7BT%28X%29+%3D+T_0%7D+f%28X%29+%5Cfrac%7Bp%28X+%5Cmid+%5Ctheta%3D%5Ctheta_0%29%7D%7B%5Cint_%7BT%28X%29%3DT_0%7D+p%28X+%5Cmid+%5Ctheta%3D%5Ctheta_0%29+dX%7D+dX.+%5Cend%7Barray%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)
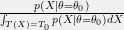 must be some function
must be some function  that depends only on
that depends only on 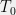 and not on
and not on 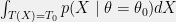 depends only on
depends only on 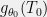 . Finally, note that
. Finally, note that 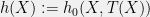 . We then see that
. We then see that  , which is the same form as (
, which is the same form as (

 and
and  , then the Fisher-Neyman condition is met; therefore,
, then the Fisher-Neyman condition is met; therefore,  is a vector of sufficient statistics for the exponential family. In fact, we can go further:
is a vector of sufficient statistics for the exponential family. In fact, we can go further: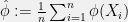 is a sufficient statistic for
is a sufficient statistic for ![\displaystyle \begin{array}{rcl} p(X_1,\ldots,X_n \mid \theta) &=& h(X_1)\cdots h(X_n) \exp(\theta^T\sum_{i=1}^n \phi(X_i) - nA(\theta)) \\ &=& h(X_1)\cdots h(X_n)\exp(n [\hat{\phi}-A(\theta)]). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+p%28X_1%2C%5Cldots%2CX_n+%5Cmid+%5Ctheta%29+%26%3D%26+h%28X_1%29%5Ccdots+h%28X_n%29+%5Cexp%28%5Ctheta%5ET%5Csum_%7Bi%3D1%7D%5En+%5Cphi%28X_i%29+-+nA%28%5Ctheta%29%29+%5C%5C+%26%3D%26+h%28X_1%29%5Ccdots+h%28X_n%29%5Cexp%28n+%5B%5Chat%7B%5Cphi%7D-A%28%5Ctheta%29%5D%29.+%5Cend%7Barray%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)
 and
and ![{g_\theta(\hat{\phi}) = \exp(n[\hat{\phi}-A(\theta)])}](https://s0.wp.com/latex.php?latex=%7Bg_%5Ctheta%28%5Chat%7B%5Cphi%7D%29+%3D+%5Cexp%28n%5B%5Chat%7B%5Cphi%7D-A%28%5Ctheta%29%5D%29%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) , we see that the Fisher-Neyman conditions are satisfied, so that
, we see that the Fisher-Neyman conditions are satisfied, so that 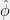 is indeed a sufficient statistic.
is indeed a sufficient statistic.  with respect to the model parameters:
with respect to the model parameters:![\displaystyle n \times \left(\hat{\phi}-\mathbb{E}[\phi \mid \theta]\right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+n+%5Ctimes+%5Cleft%28%5Chat%7B%5Cphi%7D-%5Cmathbb%7BE%7D%5B%5Cphi+%5Cmid+%5Ctheta%5D%5Cright%29+&bg=f0f0f0&fg=000000&s=0&c=20201002)
![\displaystyle n \times \left(\mathbb{E}[\phi \mid \theta]\mathbb{E}[\phi \mid \theta]^T - \mathbb{E}[\phi\phi^T \mid \theta]\right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+n+%5Ctimes+%5Cleft%28%5Cmathbb%7BE%7D%5B%5Cphi+%5Cmid+%5Ctheta%5D%5Cmathbb%7BE%7D%5B%5Cphi+%5Cmid+%5Ctheta%5D%5ET+-+%5Cmathbb%7BE%7D%5B%5Cphi%5Cphi%5ET+%5Cmid+%5Ctheta%5D%5Cright%29.+&bg=f0f0f0&fg=000000&s=0&c=20201002)
![{\mathbb{E}[X^p]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5BX%5Ep%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) . In general, if
. In general, if 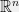 , then for every sequence
, then for every sequence  of non-negative integers, there is a corresponding moment
of non-negative integers, there is a corresponding moment ![{M_{p_1,\cdots,p_n} := \mathbb{E}[X_1^{p_1}\cdots X_n^{p_n}]}](https://s0.wp.com/latex.php?latex=%7BM_%7Bp_1%2C%5Ccdots%2Cp_n%7D+%3A%3D+%5Cmathbb%7BE%7D%5BX_1%5E%7Bp_1%7D%5Ccdots+X_n%5E%7Bp_n%7D%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) .
.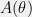 and the moments of
and the moments of ![{f(\lambda) = \mathbb{E}[\exp(\lambda^TX)]}](https://s0.wp.com/latex.php?latex=%7Bf%28%5Clambda%29+%3D+%5Cmathbb%7BE%7D%5B%5Cexp%28%5Clambda%5ETX%29%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) .
.
![{\sum_{p=0}^{\infty} \mathbb{E}[X^p] \frac{\lambda^p}{p!}}](https://s0.wp.com/latex.php?latex=%7B%5Csum_%7Bp%3D0%7D%5E%7B%5Cinfty%7D+%5Cmathbb%7BE%7D%5BX%5Ep%5D+%5Cfrac%7B%5Clambda%5Ep%7D%7Bp%21%7D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) ).
).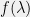 is called the moment generating function: it is the
is called the moment generating function: it is the 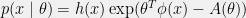 , then
, then ![{\mathbb{E}[\exp(\lambda^T\phi(x))] = \exp(A(\theta+\lambda)-A(\theta))}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B%5Cexp%28%5Clambda%5ET%5Cphi%28x%29%29%5D+%3D+%5Cexp%28A%28%5Ctheta%2B%5Clambda%29-A%28%5Ctheta%29%29%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) .
. ![\displaystyle \begin{array}{rcl} \mathbb{E}[\exp(\lambda^Tx)] &=& \int \exp(\lambda^Tx) p(x \mid \theta) dx \\ &=& \int \exp(\lambda^Tx)h(x)\exp(\theta^T\phi(x)-A(\theta)) dx \\ &=& \int h(x)\exp((\theta+\lambda)^T\phi(x)-A(\theta)) dx \\ &=& \int h(x)\exp((\theta+\lambda)^T\phi(x)-A(\theta+\lambda))dx \times \exp(A(\theta+\lambda)-A(\theta)) \\ &=& \int p(x \mid \theta+\lambda) dx \times \exp(A(\theta+\lambda)-A(\theta)) \\ &=& \exp(A(\theta+\lambda)-A(\theta)), \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cmathbb%7BE%7D%5B%5Cexp%28%5Clambda%5ETx%29%5D+%26%3D%26+%5Cint+%5Cexp%28%5Clambda%5ETx%29+p%28x+%5Cmid+%5Ctheta%29+dx+%5C%5C+%26%3D%26+%5Cint+%5Cexp%28%5Clambda%5ETx%29h%28x%29%5Cexp%28%5Ctheta%5ET%5Cphi%28x%29-A%28%5Ctheta%29%29+dx+%5C%5C+%26%3D%26+%5Cint+h%28x%29%5Cexp%28%28%5Ctheta%2B%5Clambda%29%5ET%5Cphi%28x%29-A%28%5Ctheta%29%29+dx+%5C%5C+%26%3D%26+%5Cint+h%28x%29%5Cexp%28%28%5Ctheta%2B%5Clambda%29%5ET%5Cphi%28x%29-A%28%5Ctheta%2B%5Clambda%29%29dx+%5Ctimes+%5Cexp%28A%28%5Ctheta%2B%5Clambda%29-A%28%5Ctheta%29%29+%5C%5C+%26%3D%26+%5Cint+p%28x+%5Cmid+%5Ctheta%2B%5Clambda%29+dx+%5Ctimes+%5Cexp%28A%28%5Ctheta%2B%5Clambda%29-A%28%5Ctheta%29%29+%5C%5C+%26%3D%26+%5Cexp%28A%28%5Ctheta%2B%5Clambda%29-A%28%5Ctheta%29%29%2C+%5Cend%7Barray%7D+&bg=f0f0f0&fg=000000&s=0&c=20201002)
 is a probability density and hence
is a probability density and hence  .
.  is just the
is just the  coefficient in the Taylor series for the moment generating function
coefficient in the Taylor series for the moment generating function  . Combining this with Lemma
. Combining this with Lemma 
![{\mathbb{E}[X^6]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5BX%5E6%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) , where
, where 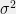 .
.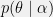 is a family that has the property that
is a family that has the property that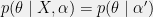
 depending on
depending on  and
and 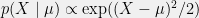 , and let
, and let  . Then, by Bayes’ rule,
. Then, by Bayes’ rule,
 parameterize a family of priors over
parameterize a family of priors over  .
. ,
, ![{\theta \in [0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta+%5Cin+%5B0%2C1%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) ,
,  , and
, and  . The distribution over
. The distribution over  is called a beta distribution. Note that
is called a beta distribution. Note that 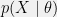 can also be written as
can also be written as  . From this, we see that the family of beta distributions is a conjugate prior to the family of Bernoulli distributions, since
. From this, we see that the family of beta distributions is a conjugate prior to the family of Bernoulli distributions, since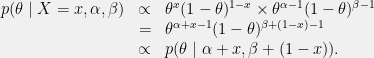
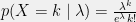 for
for 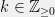 . Let
. Let  . As noted before, the distribution for
. As noted before, the distribution for  is called a Poisson distribution; the distribution for
is called a Poisson distribution; the distribution for 
 is a conjugate prior for
is a conjugate prior for  for any choice of
for any choice of  . The update formula is
. The update formula is  . Furthermore,
. Furthermore, 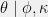 is itself an exponential family, with sufficient statistics
is itself an exponential family, with sufficient statistics ![{[\theta; A(\theta)]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Ctheta%3B+A%28%5Ctheta%29%5D%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) .
.  will be tractable; however, in many cases the conjugate prior given by Theorem
will be tractable; however, in many cases the conjugate prior given by Theorem ![{\mathbb{E}[-\log p(X)] := -\int p(x)\log(p(x)) dx}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B-%5Clog+p%28X%29%5D+%3A%3D+-%5Cint+p%28x%29%5Clog%28p%28x%29%29+dx%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) . Intuitively, higher entropy corresponds to higher uncertainty, so a maximum entropy distribution is one specifying as much uncertainty as possible given a certain set of information (such as the values of various moments). This makes them appealing, at least in theory, from a modeling perspective, since they “encode exactly as much information as is given and no more”. (Caveat: this intuition isn’t entirely valid, and in practice maximum-entropy distributions aren’t always necessarily appropriate.)
. Intuitively, higher entropy corresponds to higher uncertainty, so a maximum entropy distribution is one specifying as much uncertainty as possible given a certain set of information (such as the values of various moments). This makes them appealing, at least in theory, from a modeling perspective, since they “encode exactly as much information as is given and no more”. (Caveat: this intuition isn’t entirely valid, and in practice maximum-entropy distributions aren’t always necessarily appropriate.)![{\mathbb{E}[\phi(X)] = T}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B%5Cphi%28X%29%5D+%3D+T%7D&bg=f0f0f0&fg=000000&s=0&c=20201002) lies in the exponential family with sufficient statistic
lies in the exponential family with sufficient statistic  and
and  .
. 
![\displaystyle \frac{d}{dp}\left(-\int p(X)\log p(X) dX - \alpha [\int p(X) dX-1] - \lambda^T[\int \phi(X) p(X) dX-T]\right) = 0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7Bd%7D%7Bdp%7D%5Cleft%28-%5Cint+p%28X%29%5Clog+p%28X%29+dX+-+%5Calpha+%5B%5Cint+p%28X%29+dX-1%5D+-+%5Clambda%5ET%5B%5Cint+%5Cphi%28X%29+p%28X%29+dX-T%5D%5Cright%29+%3D+0.+&bg=f0f0f0&fg=000000&s=0&c=20201002)
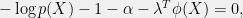

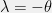 and
and  , then we recover the exponential family with
, then we recover the exponential family with 