Algebra trick of the day
I’ve decided to start recording algebra tricks as I end up using them. Today I actually have two tricks, but they end up being used together a lot. I don’t know if they have more formal names, but I call them the “trace trick” and the “rank 1 relaxation”.
Suppose that we want to maximize the Rayleigh quotient  of a matrix
of a matrix  . There are many reasons we might want to do this, for instance of is symmetric then the maximum corresponds to the largest eigenvalue. There are also many ways to do this, and the one that I’m about to describe is definitely not the most efficient, but it has the advantage of being flexible, in that it easily generalizes to constrained maximizations, etc.
. There are many reasons we might want to do this, for instance of is symmetric then the maximum corresponds to the largest eigenvalue. There are also many ways to do this, and the one that I’m about to describe is definitely not the most efficient, but it has the advantage of being flexible, in that it easily generalizes to constrained maximizations, etc.
The first observation is that is homogeneous, meaning that scaling  doesn’t affect the result. So, we can assume without loss of generality that
doesn’t affect the result. So, we can assume without loss of generality that 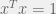 , and we end up with the optimization problem:
, and we end up with the optimization problem:
maximize 
subject to
This is where the trace trick comes in. Recall that the trace of a matrix is the sum of its diagonal entries. We are going to use two facts: first, the trace of a number is just the number itself. Second, trace(AB) = trace(BA). (Note, however, that trace(ABC) is not in general equal to trace(BAC), although trace(ABC) is equal to trace(CAB).) We use these two properties as follows — first, we re-write the optimization problem as:
maximize 
subject to 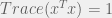
Second, we re-write it again using the invariance of trace under cyclic permutations:
maximize 
subject to 
Now we make the substitution  :
:
maximize 
subject to 
Finally, note that a matrix  can be written as
can be written as  if and only if is positive semi-definite and has rank 1. Therefore, we can further write this as
if and only if is positive semi-definite and has rank 1. Therefore, we can further write this as
maximize
subject to 
Aside from the rank 1 constraint, this would be a semidefinite program, a type of problem that can be solved efficiently. What happens if we drop the rank 1 constraint? Then I claim that the solution to this program would be the same as if I had kept the constraint in! Why is this? Let’s look at the eigendecomposition of , written as  , with
, with 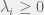 (by positive semidefiniteness) and
(by positive semidefiniteness) and 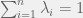 (by the trace constraint). Let’s also look at , which can be written as
(by the trace constraint). Let’s also look at , which can be written as 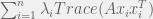 . Since is just a convex combination of the
. Since is just a convex combination of the 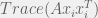 , we might as well have just picked to be
, we might as well have just picked to be 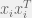 , where
, where  is chosen to maximize . If we set that
is chosen to maximize . If we set that 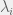 to 1 and all the rest to 0, then we maintain all of the constraints while increasing , meaning that we couldn’t have been at the optimum value of unless
to 1 and all the rest to 0, then we maintain all of the constraints while increasing , meaning that we couldn’t have been at the optimum value of unless  was equal to 1. What we have shown, then, is that the rank of must be 1, so that the rank 1 constraint was unnecessary.
was equal to 1. What we have shown, then, is that the rank of must be 1, so that the rank 1 constraint was unnecessary.
Technically, could be a linear combination of rank 1 matrices that all have the same value of , but in that case we could just pick any one of those matrices. So what I have really shown is that at least one optimal point has rank 1, and we can recover such a point from any solution, even if the original solution was not rank 1.
Here is a problem that uses a similar trick. Suppose we want to find that simultaneously satisfies the equations:
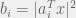
for each  (this example was inspired from the recent NIPS paper by Ohlsson, Yang, Dong, and Sastry, although the idea itself goes at least back to Candes, Strohmer, and Voroninski). Note that this is basically equivalent to solving a system of linear equations where we only know each equation up to a sign (or a phase, in the complex case). Therefore, in general, this problem will not have a unique solution. To ensure the solution is unique, let us assume the very strong condition that whenever
(this example was inspired from the recent NIPS paper by Ohlsson, Yang, Dong, and Sastry, although the idea itself goes at least back to Candes, Strohmer, and Voroninski). Note that this is basically equivalent to solving a system of linear equations where we only know each equation up to a sign (or a phase, in the complex case). Therefore, in general, this problem will not have a unique solution. To ensure the solution is unique, let us assume the very strong condition that whenever 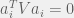 for all , the matrix
for all , the matrix 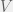 must itself be zero (note: Candes et al. get away with a much weaker condition). Given this, can we phrase the problem as a semidefinite program? I highly recommend trying to solve this problem on your own, or at least reducing it to a rank-constrained SDP, so I’ll include the solution below a fold.
must itself be zero (note: Candes et al. get away with a much weaker condition). Given this, can we phrase the problem as a semidefinite program? I highly recommend trying to solve this problem on your own, or at least reducing it to a rank-constrained SDP, so I’ll include the solution below a fold.
Solution. We can, as before, re-write the equations as:

and further write this as

As before, drop the rank 1 constraint and let 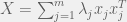 . Then we get:
. Then we get:
 ,
,
which we can re-write as 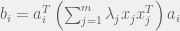 . But if
. But if 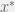 is the true solution, then we also know that
is the true solution, then we also know that  , so that
, so that  for all . By the non-degeneracy assumption, this implies that
for all . By the non-degeneracy assumption, this implies that
 ,
,
so in particular 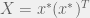 . Therefore, is the only solution to the semidefinite program even after dropping the rank constraint.
. Therefore, is the only solution to the semidefinite program even after dropping the rank constraint.

Nice! You probably have, but you should see “The Matrix Cookbook”. There are tons of great results within.
Yup! The Matrix Cookbook is awesome!